On Ops Reviews
Hello and welcome to Small Batches with me Adam Hawkins. I’m your guide to software delivery excellence. In each episode, I share a small batch of the theory and practices along the path. Topics include DevOps, lean, continuous delivery, and conversations with industry leaders. Now, let’s begin today’s episode.
I’ve received many questions on doing ops reviews, designing visual management, using SLOs, and other related topics. So I figured I’d roll it all up into single episode.
But first, it’s a new month so I have a new giveaway. This month I am giving away a free copy of the seminal book on A3 thinking: Managing to Learn by John Shook.
This book showed me how to approach practical problem-solving using the A3. I’ve done by best to apply it’s wisdom. Doing my A3s has been a game changer for me, each time leading to better outcomes and deeper problem-solving.
So find me on LinkedIn for instructions on how to enter or listen through to the end for a link.
Now, onto ops reviews.
The aim of ops reviews is to resolve production issues before they become problems. This requires two things: understanding what the system should be doing in production and understanding what the system is actually doing in production. Simple but not always easy.
Equipped with this understanding, the ops review become a process centered around these questions, then handing off information to the next person.
So let’s focus first on those two core things: what system should be doing and what the system is actually doing. Properly setup SLOs achieve both these aims. Then, more importantly, they create the visual management necessary to run ops reviews. Let me explain.
First, is the “properly defined SLO” bit. This means the SLI captures business value. Then there is an objective on delivering that business value. Here’s a real life example form the past few weeks.
One of my team is responsible for a video uploading and captioning feature. Users upload videos. Then audio is transcribed. The transcripts are used to create the captions which are then stored along with the video. This process should take a few hours.
A proper SLI for this feature is the number of uploaded videos and receiving captions in under a few hours. A proper SLO is some number of nines, it could 99%, 98%, or 99.9%, whatever number is tolerable to the business to where user satisfaction is maintained.
Poorer SLIs have to do with the component parts of the feature. While useful, they are separate from what users experience. This is a key trait for “proper” SLOs: they are rooted in the consumer experience.
Defining the SLO creates a system for delivering on the objective. That system is the error budget. SLOs are never 100% because problems are guaranteed. The error budget accepts this. Example: some videos may not have captions because of a vendor outage or the underlying cloud provider had an incident. Things under and outside your control will always contribute to the SLI.
The error budget focuses operations problems around the question: will we exhaust the error budget because of it?
This question is crucial because it cuts out the noise created from looking at error counts exclusively. Consider this scenario. You see a big jump in red bars on the error chart. Wow! I better go investigate that. Now consider this scenario. You see the same change in the error counts but no measurable change in the error budget. Wow! You just observed common cause variation. This framing shifts the thinking from total numbers to impact percentages. In other words, 1000 videos don’t have transcripts to holy crap 85% of videos don’t have transcripts. I better declare an incident ASAP!
The measurable difference in these scenario is the clear call-to-action. This brings me back to visual management and process in ops review.
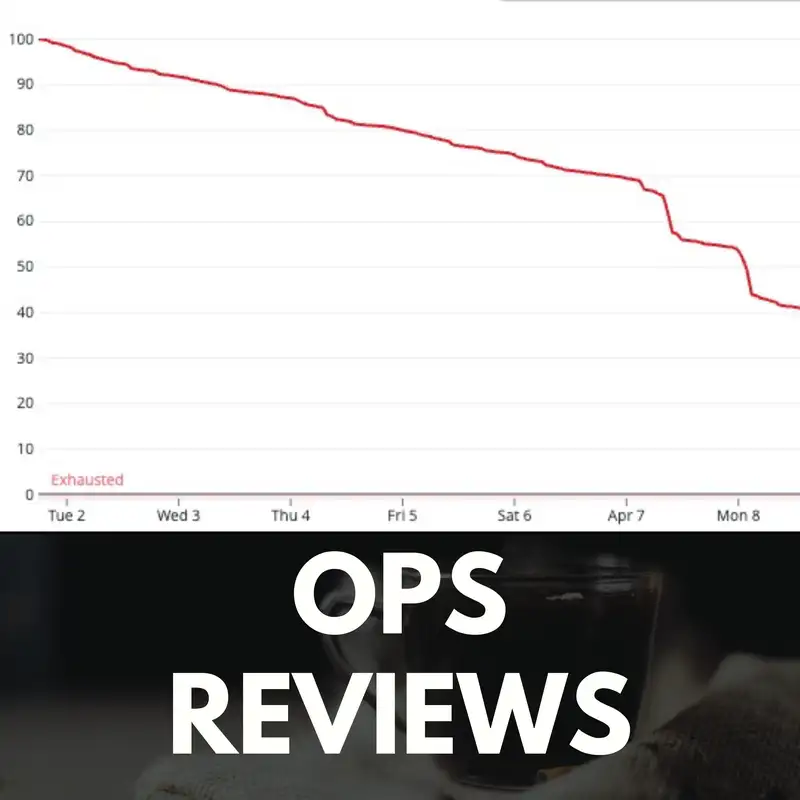
The error budget can visualized in a burn down chart. The Y axis the remaining amount. The X axis is time. Success is keeping the line above the X axis. Crossing below the X-axis means you’ve exhausted the error budget, thus missing the SLO, thus negatively impacting business value.
Now picture this. You’re looking at a dashboard with burn down charts for all your SLOs. One chart shows a horizontal line. One chart shows a line with a big dog leg in. One shows a line sloping downward but not enough to touch the X-axis. Which one of these SLOs requires attention?
The first one with a flat line requires no attention. No movement in the burn down means “system normal”. The service should meet the objective. The third one requires no attention. There is a steady turndown, but not enough to exhaust the budget. The second with the dog leg requires a second look. Does the change look like budget exhaustion? If not, what’s the cause?
That change in the burn down is the call to action. All forms of visual management exist for this aim: create the call to action. The call to action in ops review is to go and see _outside_ of the ops review meeting. The outcome of going and seeing may be fixes, it may be culling risky WIP to maintain the SLO, or it may be nothing.
This is where burn down charts are super effective. It naturally fits the blue-yellow-black grading. Error budget ok? Grade blue and move on. A new special cause contributing to excessive burn down? Grade black, call-to-action: plan go and see. Error budget, on target but close to exhaustion? Grade yellow and deal with after the blacks.
Again, the crucial CTA here is to go and see _outside_ ops review. The aim here is not to engage in deep problem solving during ops review meetings. The aim is acknowledging the call to action, then act outside the meeting.
This system lends itself to quickly grading large volumes of SLOs. Experienced engineers can quickly take in dozens of charts through visual pattern matching. This can be enhanced by leveraging color in the visual management.
If the error budget is on track, the color the burn down chart blue. If the error budget is approaching warning thresholds, then color the burn down chart yellow. If the error budget is exhausted or will be exhausted, then color the chart black. Coloring making the visual pattern matching ten times more effective.
This level of scanning cannot be achieved with bespoke charts of the golden signals because they alone cannot contextualize the impact needed to create a call-to-action. Plus, they require additional cognitive load to process. Contrast that with an SLO’s burn down chart. Understand how to use the burn down chart, then the backing SLO is irrelevant to the CTA. This scales faster and farther than bespoke dashboards.
The speed also enables a quick grading as part of the daily on-call rotation. Pull up the dashboard of burn down charts for relevant SLOs. Scan em. Grade em. Done in five to ten minutes. Record the follow up work to go and see in the team’s work tracking system.
The daily SLO grading rolls up nicely into a weekly shift hand-off report. Go over the incidents or pages that happened, note the burn downs along with any follow up work, and hand the pager off to the next person.
You can find plenty of example templates for ops review meetings and daily shift reports. You play with the format. What’s matters is guiding ops reviews with visual management that clearly communicate the CTA, then do triage and follow up work outside the meeting.
Alright, that’s all for this batch.
I need your support to keep this podcast viable. I’ve setup a patreon to support this podcast and its cousin, the Software Kaizen substack. Your support ensures I can continue producing Small Batches episodes like this one and long-form written content on Software Kaizen.
Go to SmallBatches.fm/106 to a link to my patreon, the free April giveaway, and more on SLOs.
I hope to have you back again for the next episode. Until then, happy shipping.
Creators and Guests